
Medium
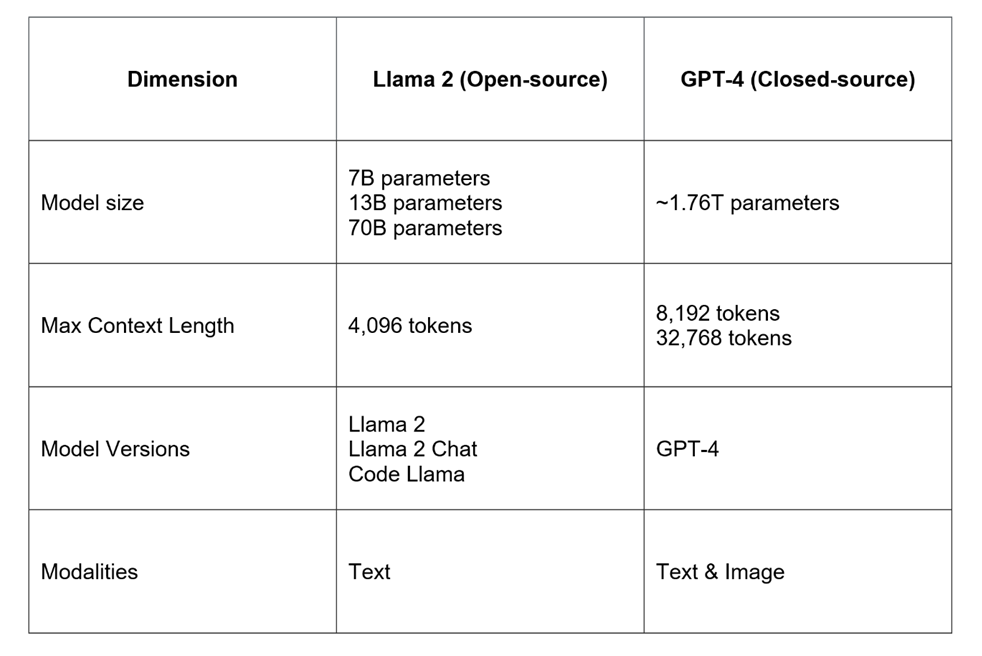
The access methods differ between the open-source Llama 2 and proprietary GPT-4 with implications for transparency costs data privacy and security Each model has its strengths and. 817 This means we should use Llama-2-70b or gpt-4 to. One of the main differences between OpenAIs GPT-4 and Metas LLaMA 2 is that the latter model is open-source As weve already mentioned above a significant advantage of open-source models is that. Of our three competitors GPT-4 is the only one able to process static visual inputs Hence if you want your software to have such a skill. LLaMA 2 developed by Meta is a versatile AI model that incorporates chatbot capabilities putting it in direct competition with similar models like OpenAIs ChatGPT..
Customize Llamas personality by clicking the settings button I can explain concepts write poems and code solve logic puzzles or. Were unlocking the power of these large language models Our latest version of Llama Llama 2 is now accessible to. Learn how to effectively use Llama 2 models for prompt engineering with our free course on. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited. For an example usage of how to integrate LlamaIndex with Llama 2 see here We also published a completed demo app showing. Welcome to the official Hugging Face organization for Llama 2 models from Meta In order to access models here. Choose from three model sizes pre-trained on 2 trillion tokens and fine-tuned with over a million human-annotated examples. What is the Llama 2 AI Model from Meta Metas Llama 2 is the newest successor and addition to the companys..

1
Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion. WEB Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters. WEB Run and fine-tune Llama 2 in the cloud Chat with Llama 2 70B. WEB We are releasing Code Llama 70B the largest and best-performing model in the Code Llama. WEB Bigger models 70B use Grouped-Query Attention GQA for improved inference scalability. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large. WEB In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large. WEB Llama 2 encompasses a series of generative text models that have been pretrained and fine-tuned..
WEB Welcome to the official Hugging Face organization for Llama 2 models from Meta In order to access models here please visit the Meta website and accept our license terms and acceptable use. WEB Llama 2 family of models Token counts refer to pretraining data only All models are trained with a global batch-size of 4M tokens Bigger models - 70B -- use Grouped-Query Attention GQA for. WEB Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration. WEB Llama 2 is here - get it on Hugging Face a blog post about Llama 2 and how to use it with Transformers and PEFT LLaMA 2 - Every Resource you need a compilation of relevant resources to. Open source free for research and commercial use Were unlocking the power of these large language models Our latest version of Llama Llama 2 is now accessible to individuals..




Komentar